
Obviously, I was planning to write an article on this topic. After my last blackfriday experience, I decided to write something about on this topic. Yes, the topic is the importance of resilience and fault tolerance in microservice architecture and how can we provide them.

The story
In my previous articles, I have always mentioned about the advantages that the microservice architecture brings to the system. If you are already reading this article, I guess, you already have an experience with the microservice architecture. I have been working on the microservice architecture for the last 3 years. Yes, I am in that transformation world too.
Life, we have already known that there is no such thing as a perfect. (isn’t it?) Every perfect thing brings a new challenge for us. We have already known and accepted all of the problems and responsibilities that comes with perfect things. Of course, sometimes we can not foresee these problems.
Anyway, actually the microservice architecture has happened to me like this. We/I have accepted some challenges that distributed systems bring to us. But we could not foresee some challenges. Yes, microservices are naturally resilient to some of the faults that can occur. When we looked at monolith applications, I guess it is not possible to ignore that the entire flow of the application is affected by a single error when an error occurs. If we think simple, we can give examples of these errors such as third-party APIs which do not respond, network splits, or no effective use of infrastructure resources. Because of these reasons, we try to build our applications in small pieces and to make sure that the entire application flow is not affected from such errors. Thus we can provide a fault tolerance to these small pieces when any error occurs. Especially in today’s age of technology, against money loss.
In summary, with microservice approach, we have totally or partially prevented the entire system flow to affected by a single error. (Of course, this is just one of the advantages.) I guess the key question here is “what should we do to make our applications, which builds of smaller pieces, more resilience and fault tolerance against these kinds of errors that can occur?”.

In this article, I will try to talk about some patterns and implementations, based on my experiences in our microservice adventure at my company I’m working at, such as Circuit breaker, Retry mechanism and Fallback operations in order to provide resilience in our applications.
Importance of Circuit breaker
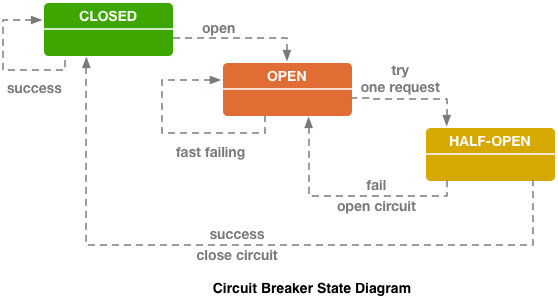
- Closed: In this mode, the circuit breaker is not open and all requests are executed.
- Open: Now the circuit breaker is open and it prevents the application from repeatedly trying to execute an operation while an error occurs.
- Half-Open: In this mode, the circuit breaker executes a few operations to identify if an error still occurs. If errors occur, then the circuit breaker will be opened, if not it will be closed.
Let’s implement a sample circuit breaker after the terminology.
First, create a class called “CircuitBreakerOptions“.
public class CircuitBreakerOptions
{
public string Key { get; set; }
public int ExceptionThreshold {get; set;}
public int SuccessThresholdWhenCircuitBreakerHalfOpenStatus { get; set; }
public TimeSpan DurationOfBreak {get; set;}
public CircuitBreakerOptions(string key, int exceptionThreshold, int successThresholdWhenCircuitBreakerHalfOpenStatus, TimeSpan durationOfBreak)
{
Key = key;
ExceptionThreshold = exceptionThreshold;
SuccessThresholdWhenCircuitBreakerHalfOpenStatus = successThresholdWhenCircuitBreakerHalfOpenStatus;
DurationOfBreak = durationOfBreak;
}
}With this class, we will get the options. We will specify with “ExceptionThreshold” property when the circuit breaker will be opened and “SuccessThresholdWhenCircuitBreakerHalfOpenStatus” property determines when the circuit breaker will be closed. We will use “DurationOfBreak” property to determine how long the circuit breaker will remain in open mode.
During the lifecycle of the application, we will define with properties from the “CircuitBreakerOptions” class, when the circuit breaker will be opened. In order to be able to define this, we have to store errors, which will occur in the application and also check the value of the “ExceptionThreshold“.
Let’s define “CircuitBreakerStateEnum” and “CircuitBreakerStateModel” class as below.
public enum CircuitBreakerStateEnum
{
Open,
HalfOpen,
Closed
}
public class CircuitBreakerStateModel
{
public CircuitBreakerStateEnum State {get; set;}
public int ExceptionAttempt {get; set;}
public int SuccessAttempt {get; set;}
public Exception LastException {get; set;}
public DateTime LastStateChangedDateUtc {get; set;}
public bool IsClosed {get; set;}
}We defined states of the circuit breaker in the enum. Also, we will use “CircuitBreakerStateModel” class to store events such as exception and success which will occur in the application.
Now let’s create the part which we will use to store the “CircuitBreakerStateModel“.
public class CircuitBreakerStateStore
{
private readonly ConcurrentDictionary<string, CircuitBreakerStateModel> _store = new ConcurrentDictionary<string, CircuitBreakerStateModel>();
public void ChangeLastStateChangedDateUtc(string key, DateTime date)
{
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
stateModel.LastStateChangedDateUtc = date;
_store[key] = stateModel;
}
}
public void ChangeState(string key, CircuitBreakerStateEnum state)
{
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
stateModel.State = state;
_store[key] = stateModel;
}
}
public int GetExceptionAttempt(string key)
{
int exceptionAttempt = 0;
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
exceptionAttempt = stateModel.ExceptionAttempt;
}
return exceptionAttempt;
}
public void IncreaseExceptionAttemp(string key)
{
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
stateModel.ExceptionAttempt += 1;
_store[key] = stateModel;
}
else
{
stateModel = new CircuitBreakerStateModel();
stateModel.ExceptionAttempt += 1;
AddStateModel(key, stateModel);
}
}
public DateTime GetLastStateChangedDateUtc(string key)
{
DateTime lastStateChangedDateUtc = default(DateTime);
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
lastStateChangedDateUtc = stateModel.LastStateChangedDateUtc;
}
return lastStateChangedDateUtc;
}
public int GetSuccessAttempt(string key)
{
int successAttempt = 0;
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
successAttempt = stateModel.SuccessAttempt;
}
return successAttempt;
}
public void IncreaseSuccessAttemp(string key)
{
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
stateModel.SuccessAttempt += 1;
_store[key] = stateModel;
}
}
public bool IsClosed(string key)
{
bool isClosed = true;
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
isClosed = stateModel.IsClosed;
}
return isClosed;
}
public void RemoveState(string key)
{
CircuitBreakerStateModel stateModel;
_store.TryRemove(key, out stateModel);
}
public void SetLastException(string key, Exception ex)
{
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
stateModel.LastException = ex;
_store[key] = stateModel;
}
}
public Exception GetLastException(string key)
{
Exception lastException = null;
CircuitBreakerStateModel stateModel;
if (_store.TryGetValue(key, out stateModel))
{
lastException = stateModel.LastException;
}
return lastException;
}
public void AddStateModel(string key, CircuitBreakerStateModel circuitBreakerStateModel)
{
_store.TryAdd(key, circuitBreakerStateModel);
}
}The only thing we did in the “CircuitBreakerStateStore” class is to store the function-based the “CircuitBreakerStateModel” class as in-memory. We will use the other methods to update or delete the state of the function-based operation.
Now we can look at the coding part of the circuit breaker. Let’s create a new class called “CircuitBreakerHelper” and implement as below.
public class CircuitBreakerHelper
{
private readonly CircuitBreakerOptions _circuitBreakerOptions;
private readonly CircuitBreakerStateStore _stateStore;
private readonly object _halfOpenSyncObject = new Object();
public CircuitBreakerHelper(CircuitBreakerOptions circuitBreakerOptions, CircuitBreakerStateStore stateStore)
{
_circuitBreakerOptions = circuitBreakerOptions;
_stateStore = stateStore;
}
public async Task<T> ExecuteAsync<T>(Func<Task<T>> func)
{
if (!IsClosed(_circuitBreakerOptions.Key))
{
if (_stateStore.GetLastStateChangedDateUtc(_circuitBreakerOptions.Key).Add(_circuitBreakerOptions.DurationOfBreak) < DateTime.UtcNow)
{
bool lockTaken = false;
try
{
Monitor.TryEnter(_halfOpenSyncObject, ref lockTaken);
if (lockTaken)
{
HalfOpen(_circuitBreakerOptions.Key);
var result = await func.Invoke();
Reset(_circuitBreakerOptions.Key);
return result;
}
}
catch (Exception ex)
{
Trip(_circuitBreakerOptions.Key, ex);
throw;
}
finally
{
if (lockTaken)
{
Monitor.Exit(_halfOpenSyncObject);
}
}
}
throw new Exception("Circuit breaker timeout hasn't yet expired.", _stateStore.GetLastException(_circuitBreakerOptions.Key));
}
try
{
var result = await func.Invoke();
return result;
}
catch (Exception ex)
{
Trip(_circuitBreakerOptions.Key, ex);
throw;
}
}
private bool IsClosed(string key)
{
return _stateStore.IsClosed(key);
}
private void HalfOpen(string key)
{
_stateStore.ChangeState(key, CircuitBreakerStateEnum.HalfOpen);
_stateStore.ChangeLastStateChangedDateUtc(key, DateTime.UtcNow);
}
private void Reset(string key)
{
_stateStore.IncreaseSuccessAttemp(key);
if (_stateStore.GetSuccessAttempt(key) >= _circuitBreakerOptions.SuccessThresholdWhenCircuitBreakerHalfOpenStatus)
{
_stateStore.RemoveState(key);
}
}
private void Trip(string key, Exception ex)
{
_stateStore.IncreaseExceptionAttemp(key);
if (_stateStore.GetExceptionAttempt(key) >= _circuitBreakerOptions.ExceptionThreshold)
{
_stateStore.SetLastException(key, ex);
_stateStore.ChangeState(key, CircuitBreakerStateEnum.Open);
_stateStore.ChangeLastStateChangedDateUtc(key, DateTime.UtcNow);
}
}
}The whole story takes place in the “ExecuteAsync” method. First, we look if the circuit breaker state for the corresponding function is open or not. If it is not in open state, we invoke the corresponding function in the below try-catch block. If any error occurs, we will catch it in the catch block, then increase the count of exception attempt in the “Trip” method and also check the value of the exception threshold. If the exception threshold value is exceeded, the state of the circuit breaker will be opened and the date will be updated on the model.
If we look at the “ExecuteAsync” method for the second flow again, we check the expire time of the circuit breaker. At the end of the expire time we create a lock to understand if the errors are still ongoing instead of closing the circuit breaker. Then we execute the operation with a single thread once again. In the “Reset” method, we check the count of the successful operations and we decide whether we close the circuit breaker or not.
So, how?
var options = new CircuitBreakerOptions(key: "CurrencyConverterSampleAPI",
exceptionThreshold: 5,
successThresholdWhenCircuitBreakerHalfOpenStatus: 5,
durationOfBreak: TimeSpan.FromMinutes(5));
CircuitBreakerHelper helper = new CircuitBreakerHelper(options, new CircuitBreakerStateStore());
var response = await helper.ExecuteAsync<T>(async () => {
// Some API call...
});In the above usage, when the circuit breaker exception threshold reaches to “5”, it will stop executing the function for “5” minutes. Thus we will ensure that infrastructure resources are not used unnecessarily and the application will be prevented from some cascading failures.
Well! Retry Mechanism?

In my opinion, retry operations are important, especially if we are working with remote resources. In many cases, unsuccessful operations usually execute successfully in the second or third retries.
Especially in distributed systems, retry operations are one of the best options that we can use against transient faults.
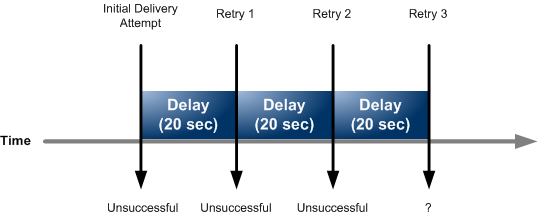
So how we can implement it?
Create a class called “RetryMechanismOptions“.
public class RetryMechanismOptions
{
public RetryPolicies RetryPolicies { get; set; }
public int RetryCount { get; set; }
public TimeSpan Interval { get; set; }
public RetryMechanismOptions(RetryPolicies retryPolicies, int retryCount, TimeSpan interval)
{
RetryPolicies = retryPolicies;
RetryCount = retryCount;
Interval = interval;
}
}
public enum RetryPolicies
{
Linear
}We will use this class to get some parameters for retry operations. We will define back-off scenarios with the “RetryPolicies” enum. In this implementation, we will only implement “Linear” policy. Also, we will determine how many times we will perform the retry operation with the “RetryCount” property.
Now let’s create an abstract class called “RetryMechanismBase“.
public abstract class RetryMechanismBase
{
private readonly RetryMechanismOptions _retryMechanismOptions;
public RetryMechanismBase(RetryMechanismOptions retryMechanismOptions)
{
_retryMechanismOptions = retryMechanismOptions;
}
public async Task<T> ExecuteAsync<T>(Func<Task<T>> func)
{
int currentRetryCount = 0;
for(;;)
{
try
{
return await func.Invoke();
}
catch(Exception ex)
{
currentRetryCount++;
bool isTransient = await IsTransient(ex);
if(currentRetryCount > _retryMechanismOptions.RetryCount || !isTransient)
{
throw;
}
}
await HandleBackOff();
}
}
protected abstract Task HandleBackOff();
private Task<bool> IsTransient(Exception ex)
{
bool isTransient = false;
var webException = ex as WebException;
if(webException != null)
{
isTransient = new[] {WebExceptionStatus.ConnectionClosed,
WebExceptionStatus.Timeout,
WebExceptionStatus.RequestCanceled,
WebExceptionStatus.KeepAliveFailure,
WebExceptionStatus.PipelineFailure,
WebExceptionStatus.ReceiveFailure,
WebExceptionStatus.ConnectFailure,
WebExceptionStatus.SendFailure}
.Contains(webException.Status);
}
return Task.FromResult(isTransient);
}
}We will perform the retry operation in the “ExecuteAsync” method with parameters, which we will get from the “RetryMechanismOptions” class. Also, we will handle back-offs in concrete classes. With the “IsTransient” method, we will decide whether the exception that might occur in the application is transient or not.
NOTE: If we want, we can provide the user to inject transient exception types in the “IsTransient” method.
Now we can implement a retry strategy. Let’s create a new class called “RetryLinearMechanismStrategy” and implement as below.
public class RetryLinearMechanismStrategy : RetryMechanismBase
{
private readonly RetryMechanismOptions _retryMechanismOptions;
public RetryLinearMechanismStrategy(RetryMechanismOptions retryMechanismOptions)
:base(retryMechanismOptions)
{
_retryMechanismOptions = retryMechanismOptions;
}
protected override async Task HandleBackOff()
{
await Task.Delay(_retryMechanismOptions.Interval);
}
}In the “HandleBackOff” method, We delayed the task with the “Interval” value set in the “RetryMechanismOptions” class.
Now we need a wrapper class to use retry operations simply. So then, let’s create a class called “RetryHelper“.
public class RetryHelper
{
public async Task<T> Retry<T>(Func<Task<T>> func, RetryMechanismOptions retryMechanismOptions)
{
RetryMechanismBase retryMechanism = null;
if(retryMechanismOptions.RetryPolicies == RetryPolicies.Linear)
{
retryMechanism = new RetryLinearMechanismStrategy(retryMechanismOptions);
}
return await retryMechanism.ExecuteAsync(func);
}
}We are done. So, how can we use it?
RetryHelper retryHelper = new RetryHelper();
var response = await helper.Retry<T>(async () => {
// Some API call...
}, new RetryMechanismOptions(retryPolicies: RetryPolicies.Linear,
retryCount: 3,
interval: TimeSpan.FromSeconds(5)));In a usage of the code sample above, if a web-based transient error occurs in the application, the operation will be retried 3 times with a 5-second interval. Hence the corresponding request will not be lost immediately.
What if affairs do not go as planned? Fallbacks!
I guess we can say that fallback is a backup strategy. In my opinion, if we design a microservice architecture, so fallback strategies are very important.

Imagine that we are working on an e-commerce website. When an order is created in the website, payment operation will be processed through the X bank’s API. Let’s assume that we were unable to process the payment operation through the X bank’s API. So, what happens now? The system has retry operations and the payment operation still cannot be processed. In such situations, fallback strategies become more important. So, instead of X bank’s API, maybe we can perform the payment operation through another bank’s API.
Summarize, fallback operations are what we decide to do when the services which we use are unavailable.
We looked at the circuit breaker, retry mechanism and fallback operations. Well, how can we use fallback operations with these patterns together?
public async Task<T> ExecuteAsync<T>(Func<Task<T>> func, string funcKey, Func<Task<T>> fallbackFunc = null)
{
try
{
// Some checks... If retry mechanism uses...blablabla
RetryHelper helper = new RetryHelper();
return await helper.Retry<T>(func, new RetryMechanismOptions(retryPolicies: RetryPolicies.Linear,
retryCount: 3,
interval: TimeSpan.FromSeconds(5)));
}
catch
{
// Some checks... If circuit breaker uses...blablabla
try
{
var options = new CircuitBreakerOptions(key: funcKey,
exceptionThreshold: 5,
successThresholdWhenCircuitBreakerHalfOpenStatus: 5,
durationOfBreak: TimeSpan.FromMinutes(5));
CircuitBreakerHelper helper = new CircuitBreakerHelper(options, new CircuitBreakerStateStore());
return await helper.ExecuteAsync(func);
}
catch (Exception)
{
if (fallbackFunc != null)
{
var result = await fallbackFunc.Invoke();
return result;
}
throw;
}
}
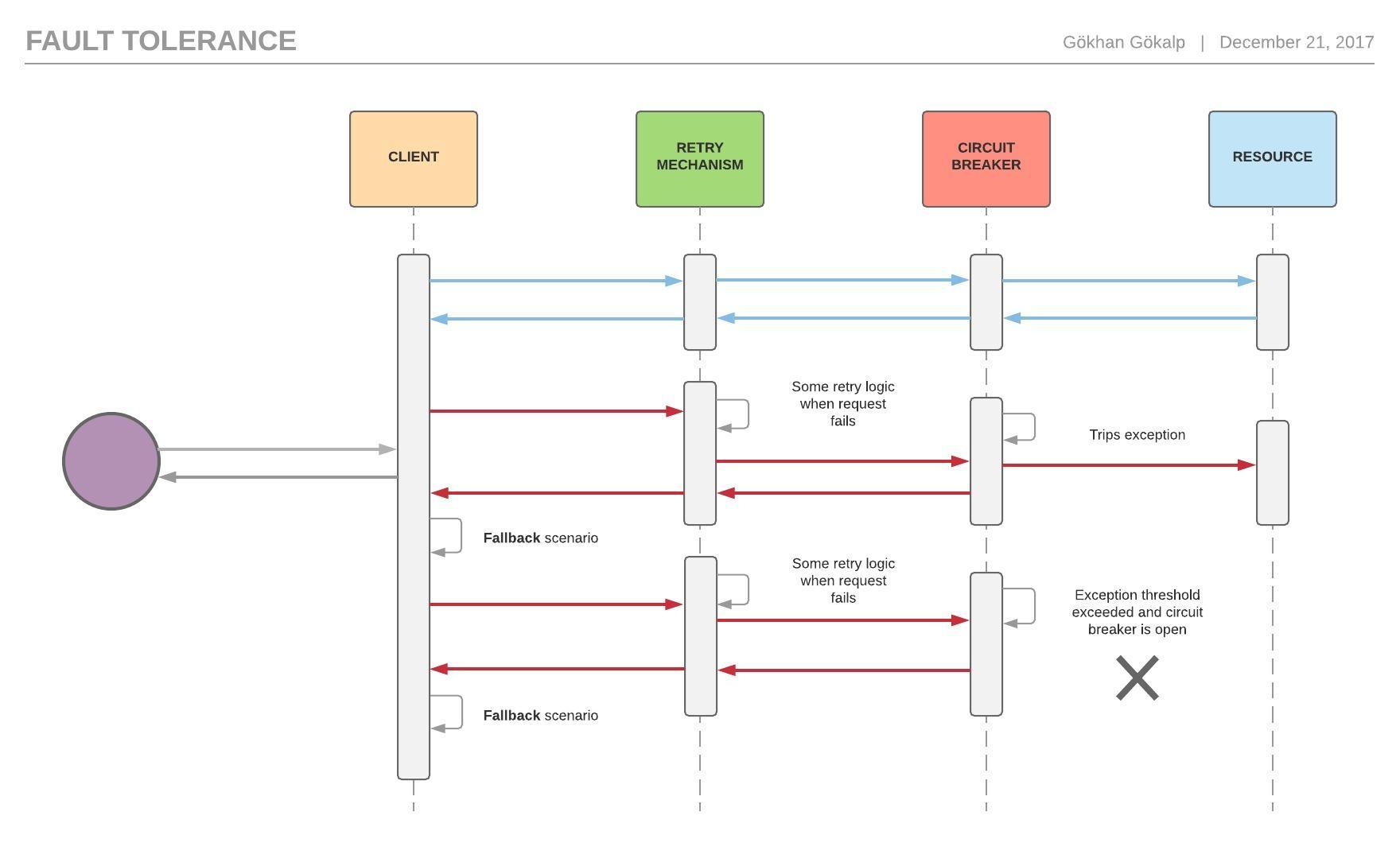
}In the method above, we use the retry operations first. If any problem occurs, we send function delegate to the circuit breaker. In case of an exception in the circuit breaker, we use the fallback function.
For better illustration, I tried to draw a sequence diagram as follow.
As I mentioned at the beginning of this article, I wanted to write this article for a long time. Now I finally did it. I hope, this article would help who needs any information about the resilience in a microservice architecture.
I have tried to talk about the importance of applications with resilience and fault-tolerance when designing microservice architecture, also how to implement them.
As conclusion as in addition how we design our applications, designing resilience capabilities of our applications in unexpected situations is also very important.
Sample project: https://github.com/GokGokalp/Luffy
References
https://docs.microsoft.com/en-us/azure/architecture/patterns/retry
https://docs.microsoft.com/en-us/azure/architecture/patterns/circuit-breaker
Mükemmel bir yazı. Türkçe dilinde ve başlangıç seviyesinin üzerinde makale görmek gerçekten umut verici, seçtiğiniz konular da çok güzel, devamını dilerim.
Microservice mimarisi kategorisindeki en iyi yazılardan birisi olduğunu sanıyorum :) Açıkçası biz de aynı problemi yaşadık. Polly kütüphanesi ile bunu tamamen aştık. Retry, Circuit Breaker, Timeout, Bulkhead Isolation, ve Fallback patternlerini de Polly ile kullanabilirsiniz.
Güzel bir yazı olmuş. Elinize sağlık
Her zaman ki gibi süpersin. Paylaşımların icin teşekkürler.
Konuların başına kazanımlar ve gereksinimler gibi küçük bir açıklama yaparsan daha güzel olcağına inanıyorum.
Melesa şu konuyu daha iyi idrak edebilmek için x,y bilmeniz gerekir.
Öncelikle bu güzel yazınız için teşekkür ederim.
Size bir sorum olacaktı,unity ile yapılan bir savaş oyununda microservice mimarisini nasıl kullanabiliriz? Yardımcı olurrsanız sevinirim.
İyi çalışmalar.