
As we know, software development doesn’t end easily especially in today’s world. In addition to developing the software, it is one of our biggest problems and responsibilities to ensure that it works properly and consistently. As we can imagine, from time to time those kinds of needs lead us to microservice architectures, event-based systems and distributed environments.
Before getting started the article, we shouldn’t forget that these architectures and patterns are not a silver bullet that will solve all our problems in one shot. We need to determine our own ways according to the business context we are in.
If we can make our choices as accurately as possible, we can do things very well. Otherwise, based on my past experiences, I can say that we may find ourselves in a situation where we are trying to solve some of the problems that our choices will bring.
In the context of this article, I would like to share with you some of my thoughts on how we can design our events while working on event-based systems.
Purpose
First of all, let’s recall some of our purposes for events. I would like to address it briefly by saying “modularity”
As we know the modularity allows us to divide the complexity and coupling of the system we are in. In this way modules can be developed by different teams as well as they can be deployed and scaled independently. On the other hand, events are one of the most basic building blocks that we can use while trying to achieve these goals.
In terms of microservice architecture, we design our applications as small as possible. We use events to provide non-blocking and asynchronous communication between applications. Thus, when an application completes a task in its own domain context, it also allows other applications to complete their tasks in their own context independently. Being independent is our key point here.
What Could Be?
We shouldn’t forget that each method that brings a solution to our problems may bring also some different problems. The same situation also applies to the decisions we make while designing events.
When we start to add more features to our applications that we try to design as small and decoupled, or when we cannot choose our domain boundaries/implementation method correctly, our applications start to become distributed coupled/dependent. In short, we may find ourselves on a journey that goes to the distributed monolith.

Name it Explicitly
How we are trying to be more specific in our daily life in order to make a subject more understandable, we should also try to be as specific as possible when naming events. Avoiding the usage of generic event naming will make events more understandable for other teams.
For example, let’s say we have an event like below.
public class ProductUpdatedEvent
{
public Guid ProductId { get; set; }
public Guid ModifiedByUserId { get; set; }
public DateTime ModifiedOn { get; set; }
}
According to the event, we can see that an update operation has been performed on the product. So, what kind of an update operation has been performed? A new product image has been added or the content of the product has been changed?
Maybe a specific action that has been performed here will enable a different action to be performed in another domain.
In short, in order to avoid confusion, we need to be specific when naming events or agree on some concepts between teams.
How Should My Event Be Designed?
Unfortunately, there is no single answer to this question. It totally depends on the domain you are working on, its boundaries and your needs. Designing the content of an event and its boundaries can be confusing most of the time, and this topic is also open to being over-engineered.
When designing the event content, you may encounter some concepts, which look the same, such as “Fat Events“, “Thin Events“, “Delta Events“, “Notification Events” and “Event-carried State Transfer“. Without causing too much confusion, I would like to talk about two simple methods that we can use when designing event content.
Thin Events
This approach does not contain much information other than ids in it. It enables other external systems to be aware of an action that has taken place within a domain.
As an example, let’s take the e-commerce scenario that I covered in my previous article.
public class OrderCreatedEvent
{
public Guid OrderId { get; set; }
public Guid UserId { get; set; }
public Guid WalletId { get; set; }
public DateTime CreatedOn { get; set; }
}
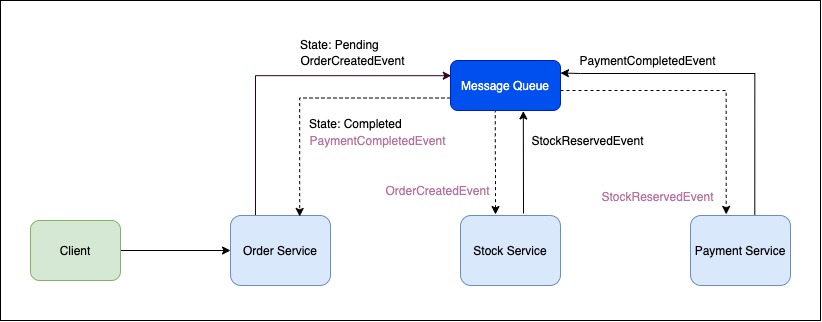
Let’s say we publish an event named “OrderCreated” when an order is created in the order domain.
In order for the order workflow to be completed, other services such as “Stock” and “Payment” which are interested in this flow, must also listen to this event and complete the necessary operations. If other services don’t have enough data to complete their operations (like in this case) they must obtain the necessary data from the resource APIs of the relevant domains by using the ids in the event.
For example, we can consider the information of the wallet where the payment will be made for the “Payment” service or the ids of the products that will be allocated by the “Stock” service. To give a different example, we may be using the CQRS approach and keeping the read-models synced with this method or different domains may be creating their own projection data.
It is one of the simplest methods to apply and start. Especially thin events might be very useful at the point where the latest version of the data is critical for the subscribers to work.
The disadvantage of this approach is that it brings back the coupling, which we try to divide and reduce with event-based systems, between systems depending on the situation. Because, if the subscriber, which is interested in the relevant change, does not have enough data to work, it must obtain the data by calling the resource APIs of the relevant domains.
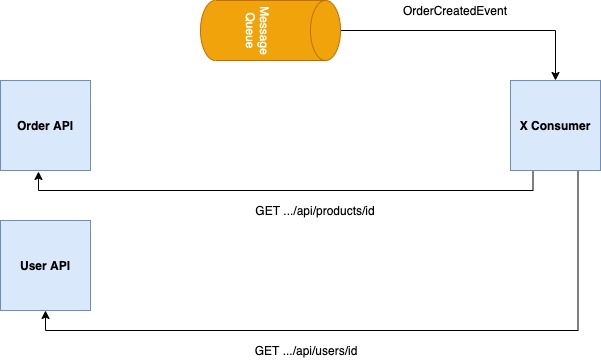
If the API of the relevant resource is not working at that time, the subscriber will not be able to perform its operation. In addition, more subscribers, that will be interested in the change, will also bring an internal overhead to the API of the relevant resource.
In order to minimize this internal overhead and coupling that may occur within the system, each service can have its own projection data. Thus, subscribers will not need to call the API of the relevant resource in case of any need and they will not be affected by failures that may occur at the publisher side. We can also think of it as having bulkhead isolation.
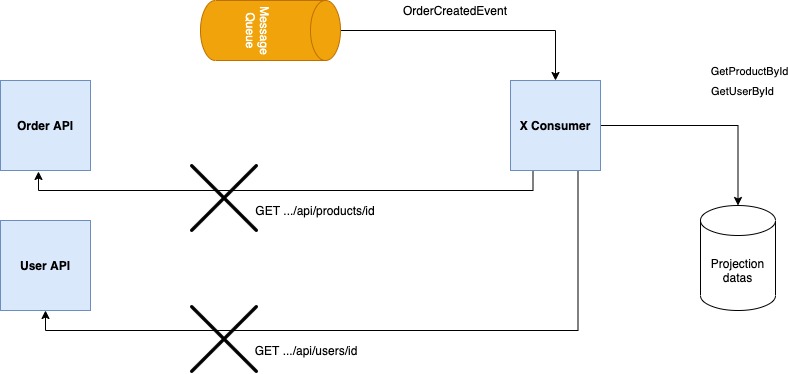
Unfortunately, although it sounds like a good solution to have, the technical complexity and eventual/data consistency that this solution will bring to the system should be accepted. Because, in order for related services to create their own projection data and keep them consistent, they should carefully handle all the relevant events which will be occurred in relevant domains.
Fat Events
In this approach, unlike thin events, an event also contains the necessary data for other subscribers to work.
For example, let’s say the “OrderCreated” event is as follows.
public class OrderCreatedEvent
{
public Guid OrderId { get; set; }
public List OderItems { get; set; }
public UserDTO User { get; set; }
public WalletDTO Wallet { get; set; }
public DateTime CreatedOn { get; set; }
}
public class OrderItemDTO
{
public Guid OrderItemId { get; set; }
public Guid ProductId { get; set; }
public string ProductName { get; set; }
public string SKU { get; set; }
public string Quantity { get; set; }
public decimal Price { get; set; }
}
public class UserDTO
{
public Guid UserId { get; set; }
public string Name { get; set; }
public string Surname { get; set; }
public string EmailAddress { get; set; }
public ShippingAddressDTO PreferredShippingAddress { get; set; }
}
public class ShippingAddressDTO
{
public string Address { get; set; }
}
public class WalletDTO
{
public Guid MasterpassWalletId { get; set; }
public Guid MasterpassCardId { get; set; }
}
In this scenario, the “OrderCreated” event contains all the data. Thus, other subscribers don’t need to call the resource APIs of the relevant domains or to have projection data. In short, unlike thin events, fat events provides better decoupling, availability and reduces network latency instead of putting a coupling between systems.
As we can see, fat events is a very useful approach in some scenarios. But as we might expect, this approach also doesn’t come perfectly. For example, if it is critical for the subscribers to work with the latest updated version of the relevant data, this method may not be very useful. Because any data in the relevant event may have been outdated at any time.
Also, we cannot ignore the contract dependency that fat events bring to the publisher. With this dependency, we cannot easily delete any data, for example, the “Wallet” object, from the event content at any time without making sure.
How difficult and complex decisions, right? When we are trying to apply a solution for a specific problem, that solution might also bring another problem to the system and we also need to find a solution for it.
Let’s Wrap It Up
The modularity capability of the event-based systems allows us to easily minimize and divide the complexity and coupling of the business we are working on.
In this article, while trying to apply the event-based approach to the domain we are in, I have tried to show how we can design our events in the simplest way and I have also tried to explain with tradeoffs.
It is quite difficult to answer the question of whether it is thin events or fat events. It completely depends on the domain context we are in, its boundaries and needs. As we have seen, although thin events bring runtime coupling to the system as a disadvantage, it also addresses problems such as if it is critical for the subscribers to work with the latest updated version of the data. In addition, it is so easy to apply and start, and it also does not add any contract dependency to the publisher.
On the other hand, fat events provide better decoupling and availability. But we need to accept some problems such as dependency and complexity that fat events bring to the publisher.
So, which approach do you prefer?
Be First to Comment